Billion-Dollar Climate Disasters
A vectorized PDF of this poster can be downloaded here.
License
The license for the code and the visual: CC BY-SA 4.0.
Introduction
Billion-Dollar Weather and Climate Disasters is a collection of data on climate disasters costing at least $1B US. This data is collected by NOAA National Centers for Environmental Information (NECI). This poster explores different aspects of those disasters and is intended to be educational. The visuals used in this poster was created with r with ggplot2, and enhanced with Adobe Illustrator.
This poster was originally created as part of the final project for Information Visualization (IST 719) at Syracuse University.
Simple Techniques on Poster’s Design
1. Viewing distances
There are three viewing distances that should be considered when putting together a poster:
- A eyecatching visual or words that can be seen from far away (i.e. the back of a classroom).
- Visuals and annotations can be seen from about half way across the room.
- Additional details that can be seen from a close distance
Keep those three distances in mind when selecting font sizes and visual sizes.
For the Billion Dollar Climate poster, the Sunburst chart was meant to be seen from far away along with the title. The different visuals and annotations are scaled to be seen from different distances.
2. Rule of the thirds
The rule of the thirds is the concept of dividing an image into a 3-by-3 grid. The intersection of the grid lines, or a third away from each of the four sides, are where people typically focus on when first viewing an image. A poster can utilize that space to help capture the eyes of the audience.
For the Billion Dollar Climate poster, the title of the poster was placed 1/3 of the way from the bottom left hand corner.
3. Color
Keep variation of color to a minimal. Color is a very powerful tool, but it can also be very distractive. With the right combination of color, one can help the audiences focus on the key message.
For the Billion Dollar Climate poster, only three primary colors were used. However, additional gradient of color was used to generate the map.
Untouched Visuals
The untouched visuals are showcased here:
They were all exported as PDF, enhanced and combined in Adobe Illustrator.
R Script
Below contains the R script that were used to generate the visuals used in this poster. Please note that this script uses the fiftystater package by Will Murphy and requires RTools to compile the package.
The R Markdown file can be obtained from Github here.
Set Up
The script detach all imported packages before importing packages. This was done to ensure that the environment is “fresh”. If a package is missing, the script would download it from CRAN (or Github).
knitr::opts_chunk$set(
warning = F,
echo = F
)
remove(list = ls(all.names = TRUE))
detachAllPackages <- function() {
basic.packages.blank <- c("stats",
"graphics",
"grDevices",
"utils",
"datasets",
"methods",
"base")
basic.packages <- paste("package:", basic.packages.blank, sep = "")
package.list <- search()[ifelse(unlist(gregexpr("package:", search())) == 1,
TRUE,
FALSE)]
package.list <- setdiff(package.list, basic.packages)
if (length(package.list) > 0) for (package in package.list) {
detach(package, character.only = TRUE)
print(paste("package ", package, " detached", sep = ""))
}
}
detachAllPackages()
graphics.off() # clear the plots
if (!require(fiftystater, quietly=TRUE)) {
if (!require(devtools)) {
install.packages('devtools')
library(devtools)
}
install_github('wmurphyrd/fiftystater')
}
pkgs <- c(
'plyr',
'tidyverse',
'lubridate',
'maps',
'png',
'grid',
'mapproj',
'stringr',
'magrittr',
'zoo',
'here'
)
if (length(pkgs) > 0) {
for (pkg in pkgs) {
if (!require(pkg,character.only=TRUE,quietly=TRUE)) {
install.packages(pkg)
library(pkg,character.only=TRUE)
}
}
}
Creating the folder paths used for this script.
dir.create(here('output'), showWarnings = FALSE)
dir.create(here('data'), showWarnings = FALSE)
data.path <- here('data')
output.path <- here('output')
Download Data
The data needed from NOAA is split into states. A simple for loop was created to download them all.
us_abb <- c(state.abb, 'US')
noaa_files <- paste0('time-series-', us_abb, '.csv')
noaa_files <- c(noaa_files,
'state-freq-data.csv',
'state-cost-data.csv',
'events-US-1980-2020.csv')
for (noaa_file in noaa_files) {
f <- file.path(data.path, noaa_file)
if (!file.exists(f)) {
download.file(paste0('https://www.ncdc.noaa.gov/billions/', noaa_file),
f, quiet = TRUE)
}
}
Data Processing
The code block below processes the different data files and compile them into a single DataFrame.
read_noaa_cost_and_frequency <- function() {
df.freq <- read.csv(file.path(data.path, 'state-freq-data.csv'), skip = 1)
df.cost <- read.csv(file.path(data.path, 'state-cost-data.csv'), skip = 1)
colnames(df.freq) <- str_to_title(gsub('\\.', ' ', colnames(df.freq)))
colnames(df.freq) <- paste0(gsub(' ', '_', colnames(df.freq)), '_Count')
colnames(df.cost) <- str_to_title(gsub('\\.', ' ', colnames(df.cost)))
colnames(df.cost) <- paste0(gsub(' ', '_', colnames(df.cost)), '_Cost')
df.freq %<>%
select(-Year_Count) %>%
rename(State = State_Count) %>%
group_by(State) %>%
summarize_all(sum) %>%
mutate(Year = 'All')
df.cost %<>%
rename(State = State_Cost) %>%
group_by(State) %>%
summarize_all(sum)
return(merge(df.freq, df.cost, 'State'))
}
read_noaa_time_series <- function(state_abb) {
f <- file.path(data.path, paste0('time-series-', state_abb, '.csv'))
df <- read.csv(f,
skip=2)
colnames(df) <- gsub("\\.", "_", colnames(df))
if (state_abb == 'US') {
df %<>%
mutate(State = state_abb) %>%
select(c('State', 'Year',
'Drought_Count', 'Drought_Cost', 'Drought_Lower_95', 'Drought_Upper_95',
'Flooding_Count', 'Flooding_Cost', 'Flooding_Lower_95', 'Flooding_Upper_95',
'Freeze_Count', 'Freeze_Cost', 'Freeze_Lower_95', 'Freeze_Upper_95',
'Severe_Storm_Count', 'Severe_Storm_Cost', 'Severe_Storm_Lower_95', 'Severe_Storm_Upper_95',
'Tropical_Cyclone_Count', 'Tropical_Cyclone_Cost', 'Tropical_Cyclone_Lower_95', 'Tropical_Cyclone_Upper_95',
'Wildfire_Count', 'Wildfire_Cost','Wildfire_Lower_95', 'Wildfire_Upper_95',
'Winter_Storm_Count', 'Winter_Storm_Cost', 'Winter_Storm_Lower_95', 'Winter_Storm_Upper_95'
)) %>%
mutate(State = state_abb) %>%
rename_all(list(~ str_replace(., '_95', '_Cost')))
} else {
df %<>%
mutate(State = state_abb) %>%
select(c('State', 'Year',
'Drought_Count', 'Drought_Cost_Range',
'Flooding_Count', 'Flooding_Cost_Range',
'Freeze_Count', 'Freeze_Cost_Range',
'Severe_Storm_Count', 'Severe_Storm_Cost_Range',
'Tropical_Cyclone_Count', 'Tropical_Cyclone_Cost_Range',
'Wildfire_Count', 'Wildfire_Cost_Range',
'Winter_Storm_Count', 'Winter_Storm_Cost_Range'
)) %>%
separate(Drought_Cost_Range, into = c('Drought_Lower_Cost', 'Drought_Upper_Cost'), sep = '-') %>%
separate(Flooding_Cost_Range, into = c('Flooding_Lower_Cost', 'Flooding_Upper_Cost'), sep = '-') %>%
separate(Freeze_Cost_Range, into = c('Freeze_Lower_Cost', 'Freeze_Upper_Cost'), sep = '-') %>%
separate(Severe_Storm_Cost_Range, into = c('Severe_Storm_Lower_Cost', 'Severe_Storm_Upper_Cost'), sep = '-') %>%
separate(Tropical_Cyclone_Cost_Range, into = c('Tropical_Cyclone_Lower_Cost', 'Tropical_Cyclone_Upper_Cost'), sep = '-') %>%
separate(Wildfire_Cost_Range, into = c('Wildfire_Lower_Cost', 'Wildfire_Upper_Cost'), sep = '-') %>%
separate(Winter_Storm_Cost_Range, into = c('Winter_Storm_Lower_Cost', 'Winter_Storm_Upper_Cost'), sep = '-') %>%
mutate_at(vars(ends_with('Cost')), list(as.integer)) %>%
mutate(Drought_Cost = (Drought_Lower_Cost + Drought_Upper_Cost)/2,
Flooding_Cost = (Flooding_Lower_Cost + Flooding_Upper_Cost)/2,
Freeze_Cost = (Freeze_Lower_Cost + Freeze_Upper_Cost)/2,
Severe_Storm_Cost = (Severe_Storm_Lower_Cost + Severe_Storm_Upper_Cost)/2,
Tropical_Cyclone_Cost = (Tropical_Cyclone_Lower_Cost + Tropical_Cyclone_Upper_Cost)/2,
Wildfire_Cost = (Wildfire_Lower_Cost + Wildfire_Upper_Cost)/2,
Winter_Storm_Cost = (Winter_Storm_Lower_Cost + Winter_Storm_Upper_Cost)/2) %>%
mutate_at(vars(ends_with('Cost')), function (x) x/1000) %>%
select(c('State', 'Year',
'Drought_Count', 'Drought_Cost', 'Drought_Lower_Cost', 'Drought_Upper_Cost',
'Flooding_Count', 'Flooding_Cost', 'Flooding_Lower_Cost', 'Flooding_Upper_Cost',
'Freeze_Count', 'Freeze_Cost', 'Freeze_Lower_Cost', 'Freeze_Upper_Cost',
'Severe_Storm_Count', 'Severe_Storm_Cost', 'Severe_Storm_Lower_Cost', 'Severe_Storm_Upper_Cost',
'Tropical_Cyclone_Count', 'Tropical_Cyclone_Cost', 'Tropical_Cyclone_Lower_Cost', 'Tropical_Cyclone_Upper_Cost',
'Wildfire_Count', 'Wildfire_Cost','Wildfire_Lower_Cost', 'Wildfire_Upper_Cost',
'Winter_Storm_Count', 'Winter_Storm_Cost', 'Winter_Storm_Lower_Cost', 'Winter_Storm_Upper_Cost'
))
}
return(df)
}
read_us_events <- function() {
df <- read.csv(file.path(data.path, 'events-US-1980-2020.csv'), skip = 1)
df %<>%
mutate(Begin.Date = strptime(Begin.Date, format = '%Y%m%d'),
End.Date = strptime(End.Date, format = '%Y%m%d'),
Year = year(Begin.Date))
df %<>%
group_by(Year, Disaster) %>%
summarize(Cost = sum(Total.CPI.Adjusted.Cost..Millions.of.Dollars.)/1000,
Count = n(),
Death = sum(Deaths)) %>%
mutate(State = 'US',
Region = 'United States')
return(df)
}
clean_data_set_further <- function(df) {
df.freq <- df %>%
select('State', 'Year' | ends_with("Count")) %>%
pivot_longer(-c('State', 'Year'), names_to = 'Disaster', values_to = 'Count') %>%
mutate(Disaster = gsub('_Count', '', Disaster),
Disaster = gsub('_', ' ', Disaster))
df.cost <- df %>%
select('State', 'Year' | ends_with("Cost")) %>%
pivot_longer(-c('State', 'Year'), names_to = 'Disaster', values_to = 'Cost') %>%
mutate(Disaster = gsub('_Cost', '', Disaster),
Disaster = gsub('_', ' ', Disaster))
df <- merge(df.freq, df.cost,
sort = FALSE,
by = c('State', 'Year', 'Disaster'))
states_name_to_abb <- tibble(Region = state.name) %>%
bind_cols(tibble(State = state.abb))
df <- merge(states_name_to_abb, df,
sort = FALSE,
by = 'State')
return(df)
}
df.raw <- plyr::ldply(.data = us_abb,
.fun = read_noaa_time_series)
df.raw %<>% select(c('State', 'Year',
'Drought_Count', 'Drought_Cost',
'Flooding_Count', 'Flooding_Cost',
'Freeze_Count', 'Freeze_Cost',
'Severe_Storm_Count', 'Severe_Storm_Cost',
'Tropical_Cyclone_Count', 'Tropical_Cyclone_Cost',
'Wildfire_Count', 'Wildfire_Cost',
'Winter_Storm_Count', 'Winter_Storm_Cost'))
df.raw <- clean_data_set_further(rbind(df.raw, read_noaa_cost_and_frequency()))
df.raw$Death = 0
df.raw <- rbind(df.raw, read_us_events())
This determines the dimension of the DataFrame.
dim(df.raw)
Chart Creation
Selection of color
The hex code for the three main colors used in this poster.
primary_color = '#f4a261'
secondary_color = '#2a9d8f'
bg_color = '#264653'
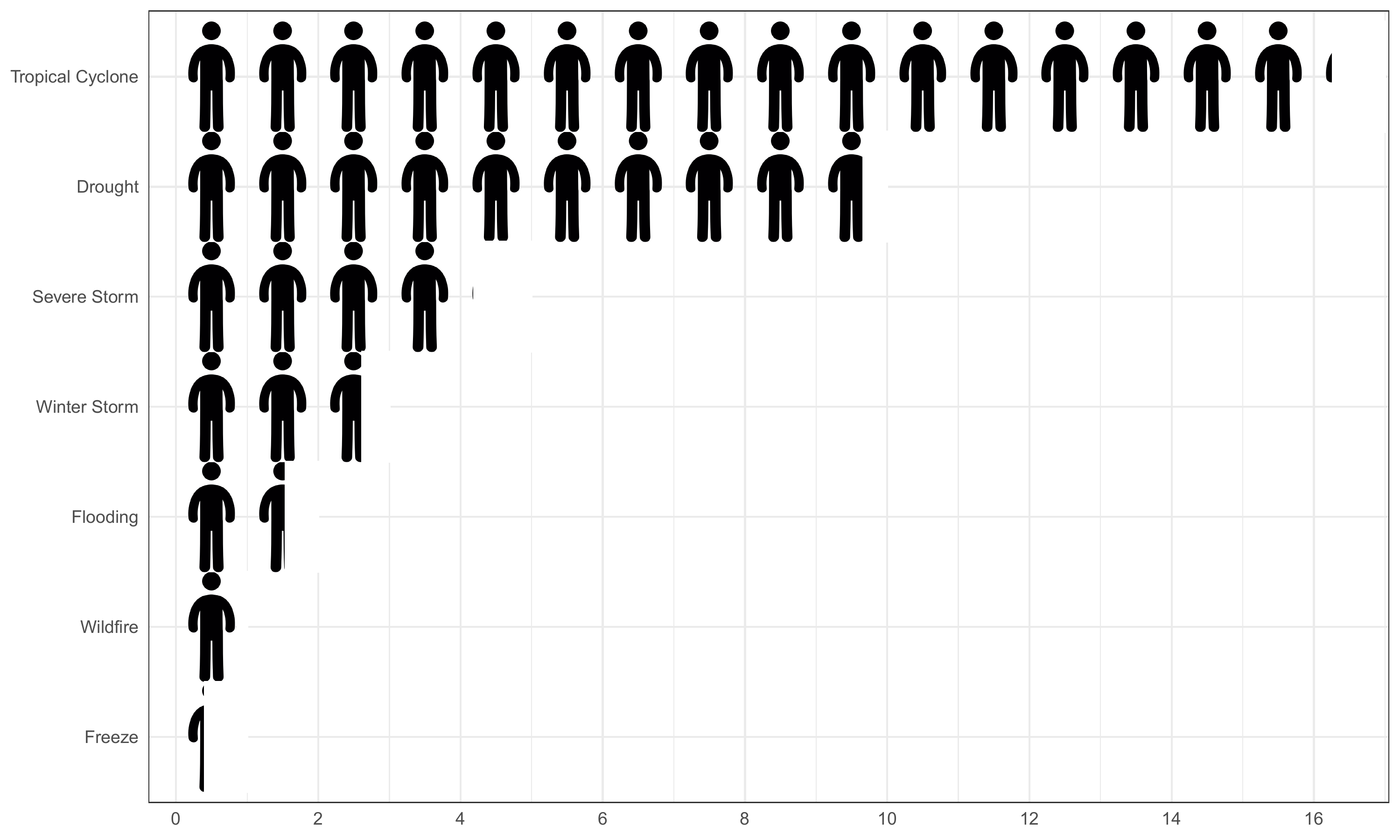
Pictogram of United States’ Deaths by Climate Disaster Type
df.us.death_by_disaster <- df.raw %>%
filter(State == 'US',
Year < 2020) %>%
group_by(Disaster) %>%
summarize(Ten_Death_per_Year = sum(Death)/400) %>%
arrange(Ten_Death_per_Year)
fill_images <- function() {
l <- list()
for (r in 1:nrow(df.us.death_by_disaster)) {
for (d in 1:ceiling(df.us.death_by_disaster$Ten_Death_per_Year[r])) {
img <- readPNG(file.path(data.path, 'person.png'))
g <- rasterGrob(img, interpolate = T)
l <- c(l, annotation_custom(
g,
xmin = r-1/2,
xmax = r+1/2,
ymin = d-1,
ymax = d))
}
}
l
}
clip_images <- function() {
l <- list()
for (r in 1:nrow(df.us.death_by_disaster)) {
l <- c(l, geom_rect(
xmin = r-1/2,
xmax = r+1/2,
ymin = df.us.death_by_disaster$Ten_Death_per_Year[r],
ymax = ceiling(df.us.death_by_disaster$Ten_Death_per_Year[r]),
color = 'white', fill = 'white'))
}
l
}
df.us.death_by_disaster
ggplot(df.us.death_by_disaster,
aes(reorder(Disaster, Ten_Death_per_Year), Ten_Death_per_Year)) +
fill_images() +
clip_images() +
scale_y_continuous(breaks=seq(0, 20, 2)) +
scale_x_discrete() +
theme_bw() +
theme(legend.position = 'none',
axis.title.x = element_blank(),
axis.title.y = element_blank(),
axis.ticks = element_blank()) +
coord_flip()
ggsave(file.path(output.path,'pictogram_death_by_disaster.pdf'),
width = 10, height = 6, units = 'in')
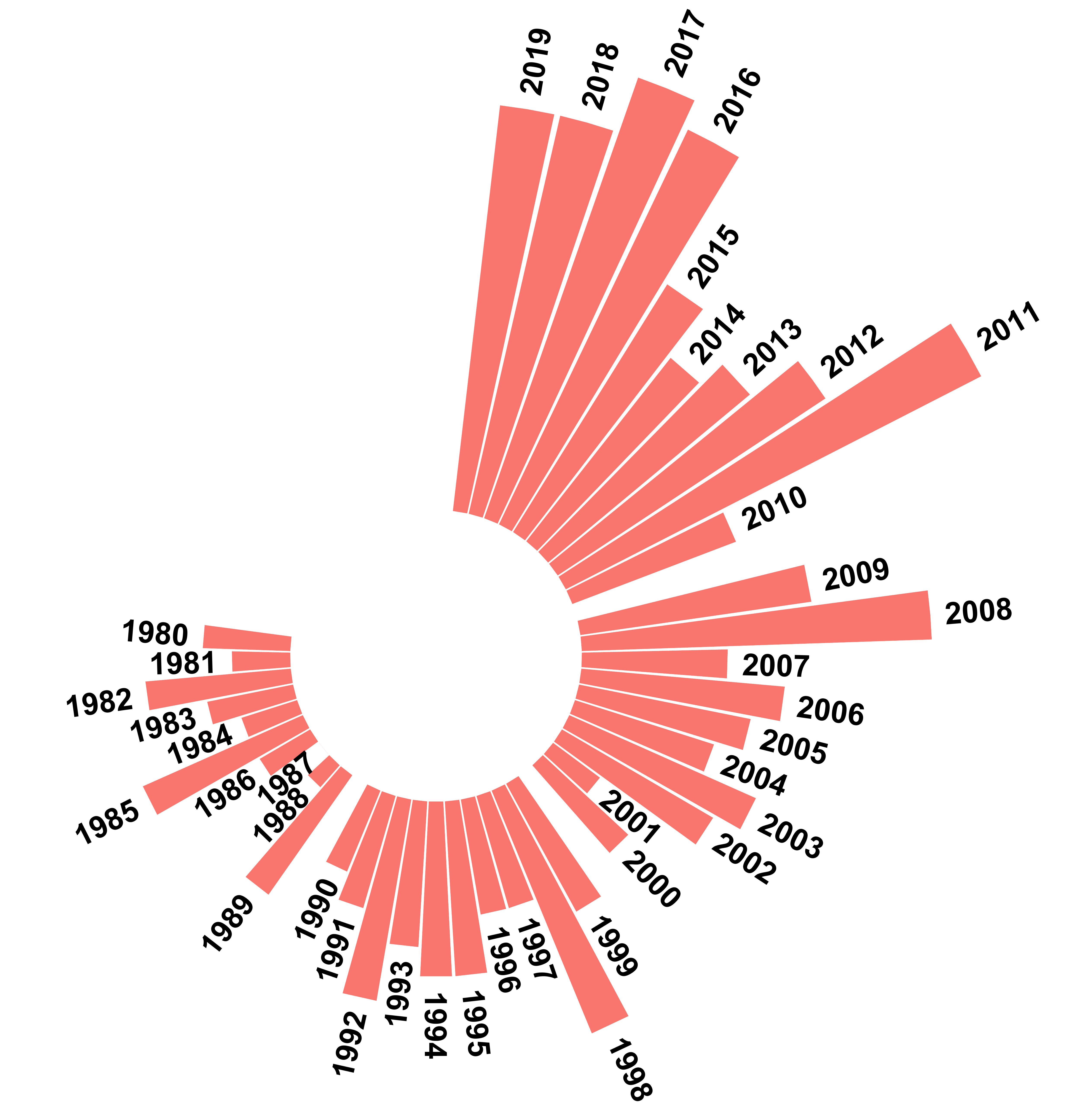
Sunburst Chart of United States’ Frequency of Climate Disasters by Year
df.us.count_by_disaster <- df.raw %>%
filter(State == 'US',
Year < 2020) %>%
mutate(Year = as.integer(Year)) %>%
group_by(Year) %>%
summarize(
Count = sum(Count)) %>%
complete(Year = c(1980:2019)) %>%
mutate(Count = coalesce(Count, 0),
Decade = as.factor(paste0(as.character(Year - (Year %% 10)),'s')))
empty_bar <- 1
to_add <- data.frame(
matrix(NA,
empty_bar*nlevels(df.us.count_by_disaster$Decade),
ncol(df.us.count_by_disaster)))
colnames(to_add) <- colnames(df.us.count_by_disaster)
to_add$Decade <- rep(levels(df.us.count_by_disaster$Decade), each=empty_bar)
df.us.count_by_disaster <- rbind(df.us.count_by_disaster, to_add)
empty_bar <- 13
to_add <- data.frame(
matrix(NA,
empty_bar,
ncol(df.us.count_by_disaster)))
colnames(to_add) <- colnames(df.us.count_by_disaster)
to_add$Decade <- first(df.us.count_by_disaster$Decade)
df.us.count_by_disaster <- rbind(to_add, df.us.count_by_disaster)
df.us.count_by_disaster <- df.us.count_by_disaster %>% arrange(Decade)
df.us.count_by_disaster$id <- seq(1, nrow(df.us.count_by_disaster))
df.us.count_by_disaster <- df.us.count_by_disaster %>% arrange(-id)
df.us.count_by_disaster$id <- seq(1, nrow(df.us.count_by_disaster))
label_data <- df.us.count_by_disaster
number_of_bar <- nrow(label_data)
angle <- 90 - 360 * (label_data$id-0.5) /number_of_bar
label_data$hjust <- ifelse( angle < -90, 1, 0)
label_data$angle <- ifelse(angle < -90, angle+180, angle)
# Make the plot
ggplot(df.us.count_by_disaster, aes(x=as.factor(id), y=Count, fill=primary_color)) +
geom_bar(aes(x=as.factor(id), y=Count, fill=primary_color), stat='identity') +
ylim(-5,17) +
theme_minimal() +
theme(
legend.position = "none",
axis.text = element_blank(),
axis.title = element_blank(),
panel.grid = element_blank(),
plot.margin = unit(rep(-1,4), 'cm')
) +
coord_polar() +
geom_text(data=label_data, aes(x=id, y=Count+0.5, label=as.character(Year), hjust=hjust), color='black', fontface='bold',alpha=1, size=12, angle= label_data$angle, inherit.aes = FALSE )
ggsave(file.path(output.path,'circular_pie_frequency_by_year.pdf'),
width = 24, height = 24, units = 'in')
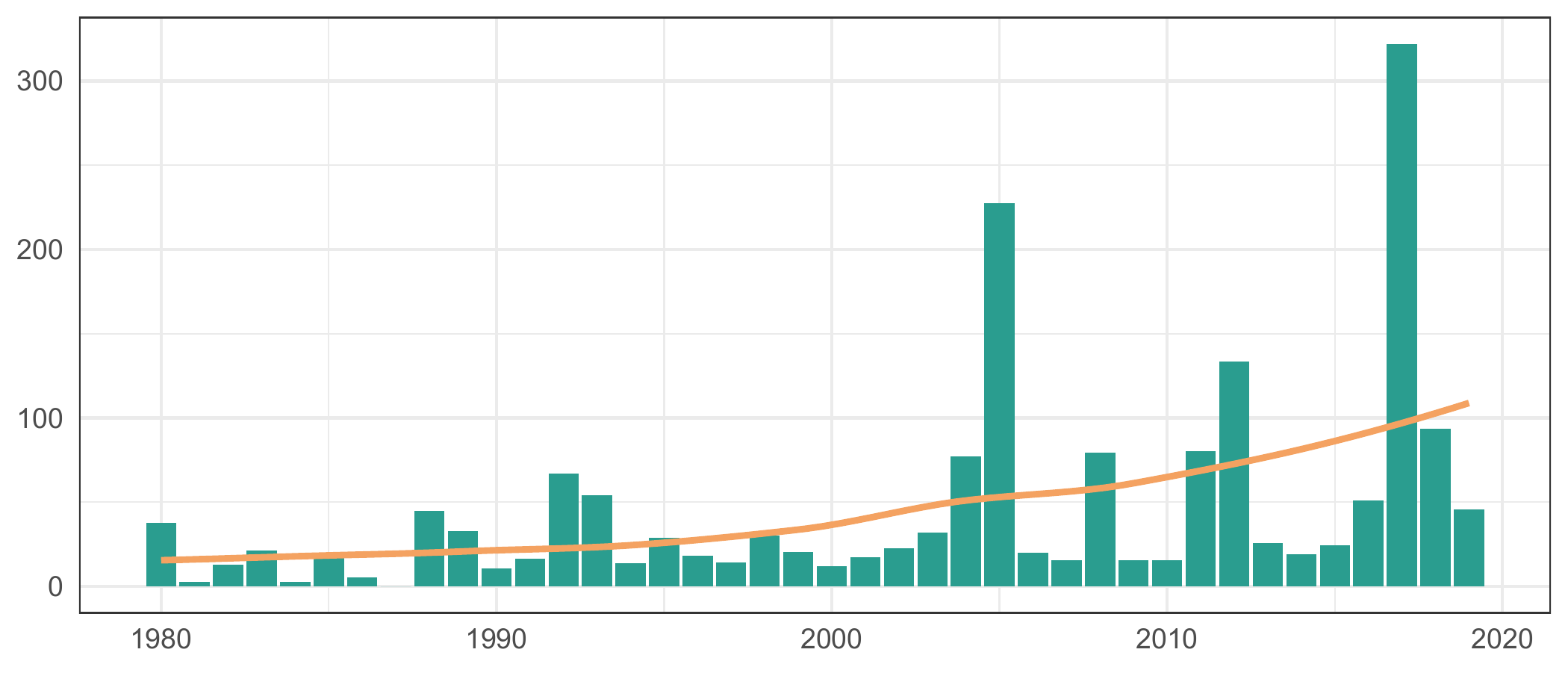
Bar Chart of United States’ Spend on Climate Disasters by Year
df.us.cost_per_year <- df.raw %>%
mutate(Year = as.integer(Year)) %>%
filter(State == 'US',
Year < 2020) %>%
group_by(Year) %>%
summarize(Cost = sum(Cost)) %>%
complete(Year = c(1980:2019)) %>%
mutate(Cost = coalesce(Cost, 0),
Decade = as.factor(paste0(as.character(Year - (Year %% 10)),'s')))
df.us.cost_per_year %>% group_by(Decade) %>% summarize(Cost = mean(Cost))
ggplot(df.us.cost_per_year, aes(x = Year, y = Cost)) +
geom_bar(stat = 'identity', fill = secondary_color) +
geom_smooth(formula = y~x, method = 'loess', se = FALSE, color = primary_color) +
theme_bw() +
theme(legend.position = 'none',
axis.title.x = element_blank(),
axis.title.y = element_blank(),
axis.ticks = element_blank())
ggsave(file.path(output.path,'bar_cost_per_year.pdf'),
width = 7, height = 3, units = 'in')
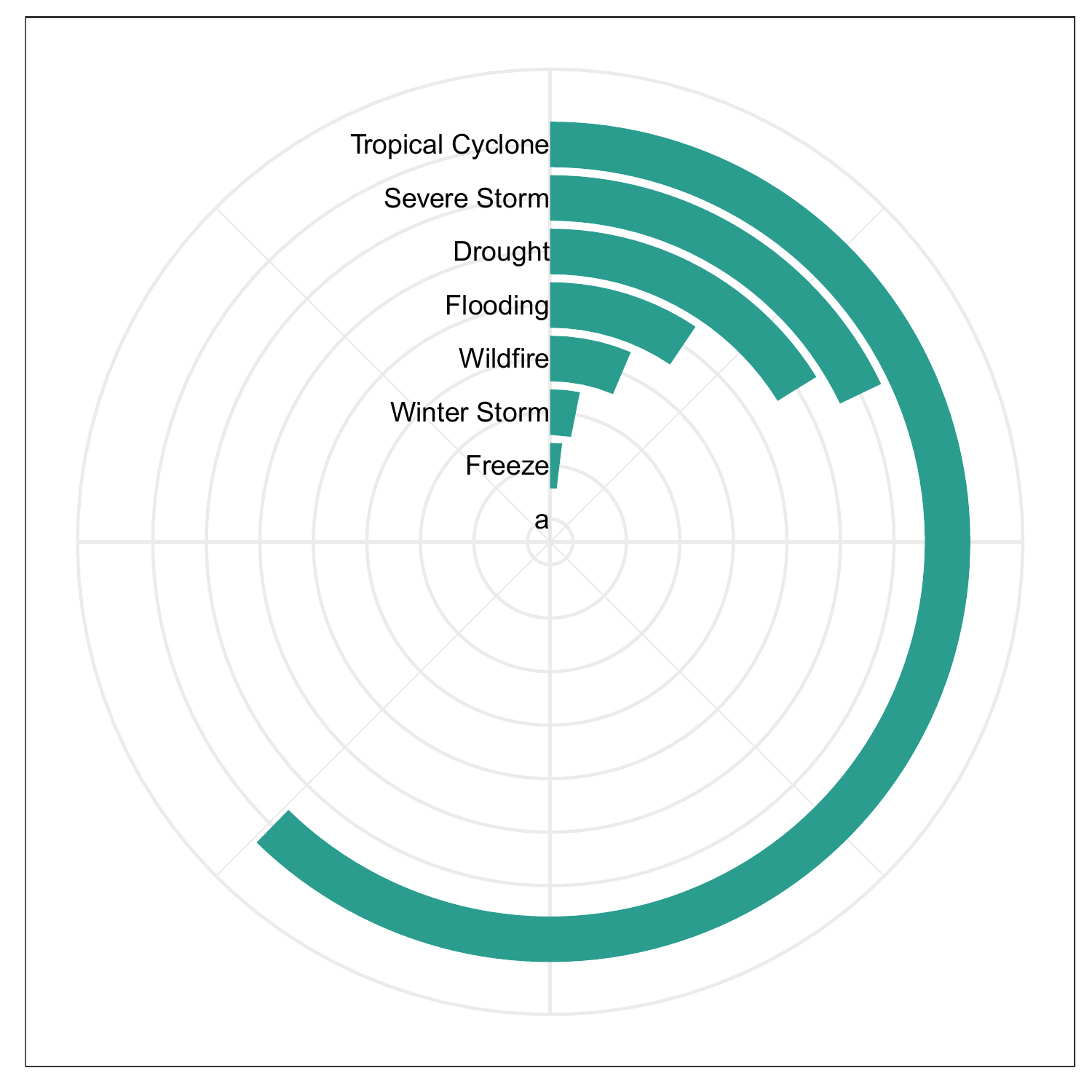
Circular Bar Chart of Cost by Climate Disaster Type
The reason this was made into a circular bar chart instead of a regular bar chart is because of spacing.
max_percent = 62.5
df.us.cost_by_disaster <- df.raw %>%
filter(State == 'US') %>%
group_by(Disaster) %>%
summarize(Cost = sum(Cost)) %>%
mutate(Percent = Cost/1000*max_percent)
empty_bar <- 1
to_add <- data.frame(
matrix(0,
empty_bar,
ncol(df.us.cost_by_disaster)))
colnames(to_add) <- colnames(df.us.cost_by_disaster)
to_add$Disaster <- letters[1:empty_bar]
df.us.cost_by_disaster <- rbind(df.us.cost_by_disaster, to_add)
ggplot(df.us.cost_by_disaster, aes(x = reorder(Disaster, Cost), y = Percent)) +
geom_bar(width = 0.85, stat = 'identity', fill = secondary_color) +
coord_polar(theta = 'y') +
ylim(c(0,100)) +
geom_text(data = df.us.cost_by_disaster,
hjust = 1,
size = 3,
aes(x = Disaster,
y = 0,
label = Disaster))+
theme_bw() +
theme(legend.position = 'none',
axis.text.x = element_blank(),
axis.text.y = element_blank(),
axis.title.x = element_blank(),
axis.title.y = element_blank(),
axis.ticks = element_blank())
ggsave(file.path(output.path,'radial_bar_cost_by_disaster.pdf'),
width = 5, height = 5, units = 'in')
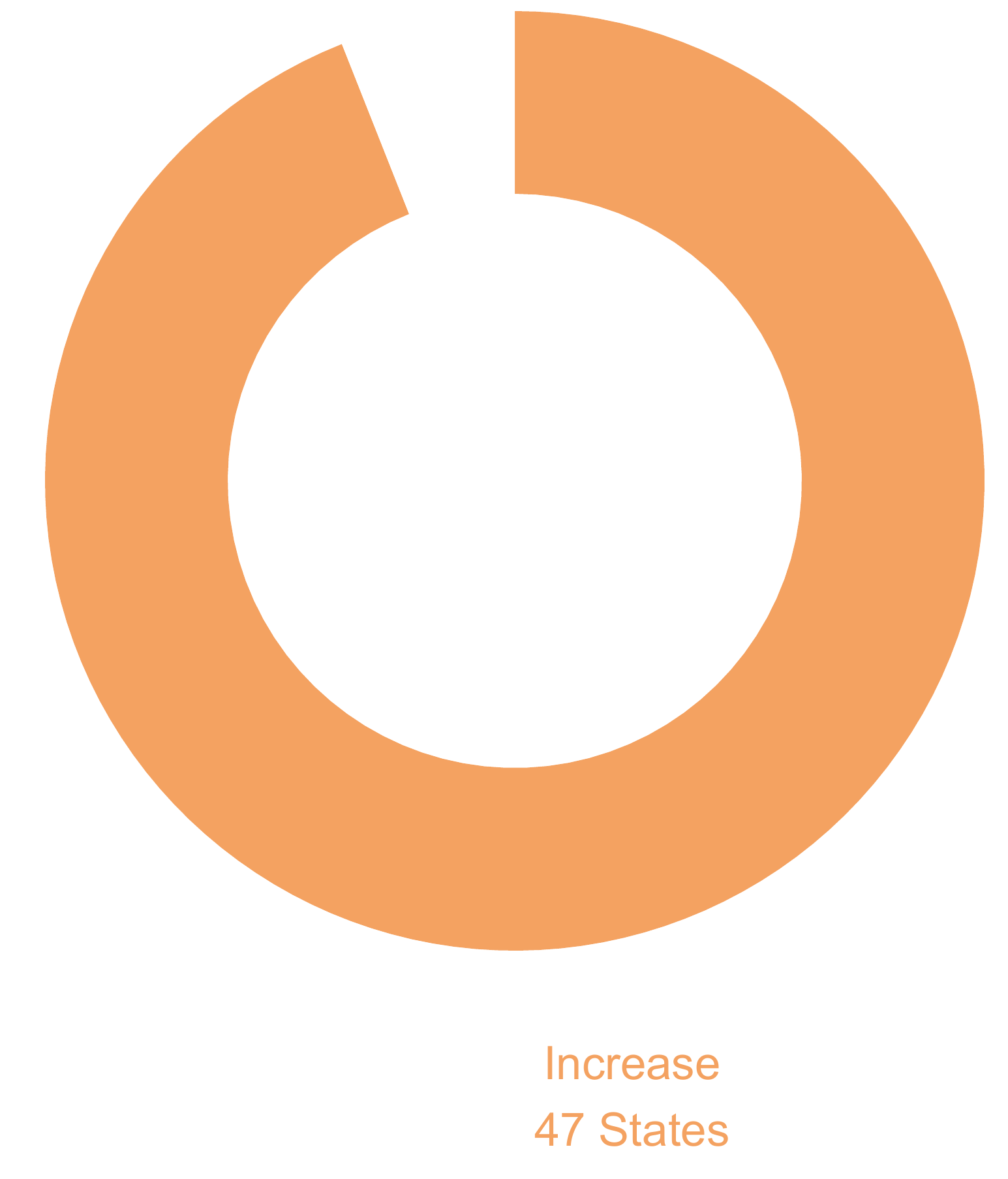
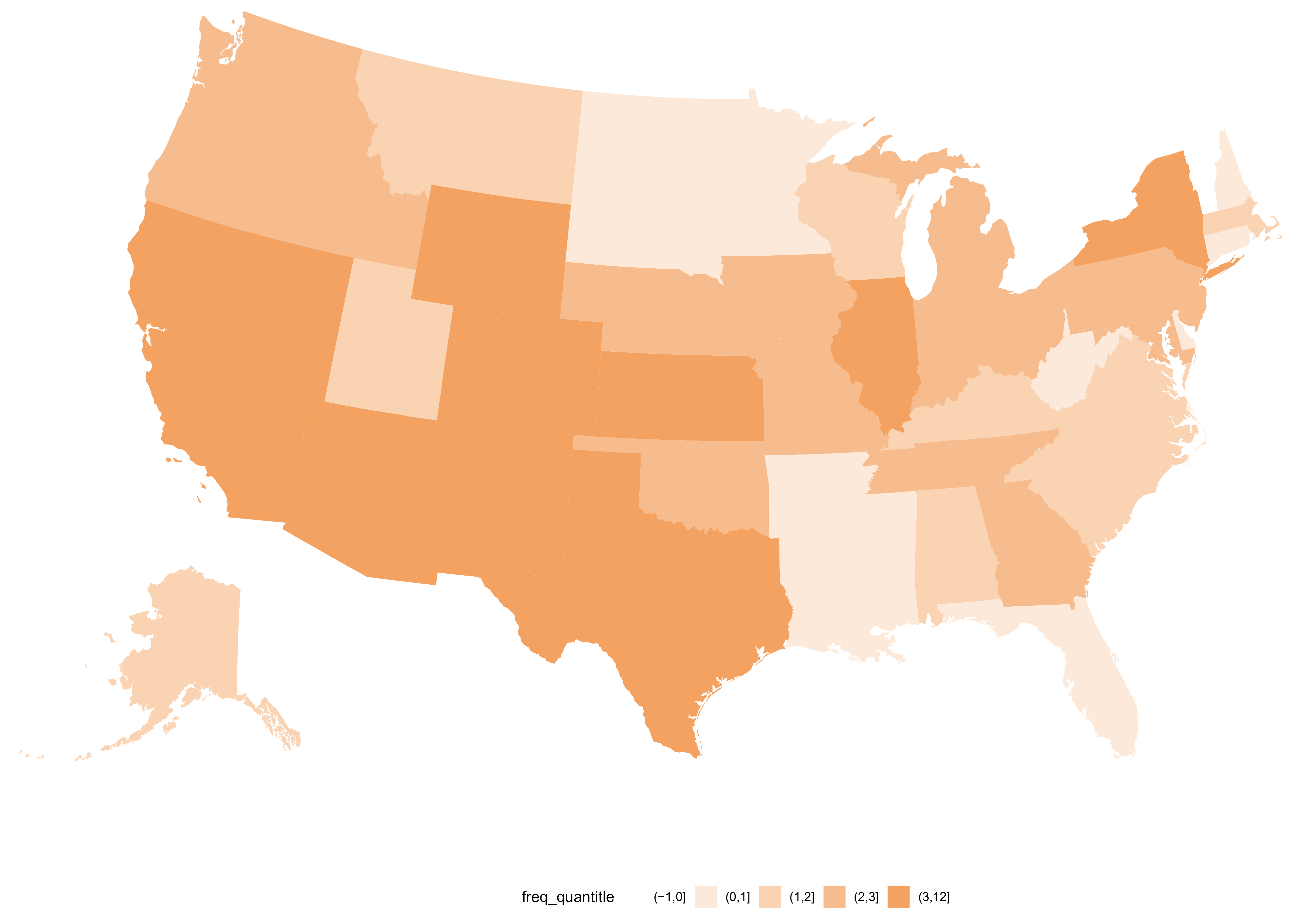
Map of Frequency Change in Climate Disasters by State
This code block also creates a donut chart of the percentage of states that saw an increase in frequency of climate disasters.
tiles <- c(-1,0,1,2,3,12)
df.state.freq_by_decade <- df.raw %>%
filter((!Year %in% c(2020, 'All')),
(State != 'US')) %>%
mutate(Year = as.integer(Year),
Decade = Year - (Year %% 10)) %>%
group_by(Decade, Region) %>%
summarize(Count = sum(Count)) %>%
filter(Decade %in% c(1980, 2010)) %>%
spread(Decade, value = Count) %>%
mutate(Difference = `2010` - `1980`,
Percent_Increase = ifelse(`1980`>0,Difference/`1980`,`2010`),
Group = ifelse(Difference > 0, 'Increase', ifelse(Difference == 0, 'No Change', 'Decrease')),
freq_quantitle = cut(
Percent_Increase,
breaks = tiles,include.lowest = FALSE))
df.state.freq_change <- df.state.freq_by_decade %>%
mutate(Group = as.factor(Group)) %>%
group_by(Group) %>%
summarize(Count = n()) %>%
mutate(fraction = Count/sum(Count),
ymax = cumsum(fraction),
ymin = c(0, head(ymax, n=-1)),
labelPosition = (ymax + ymin) / 2,
label = paste0(Group, '\n', Count, ' States'))
ggplot(df.state.freq_change,
aes(ymax=ymax,
ymin=ymin,
xmax=3.5,
xmin=1.75,
fill=as.factor(Group))) +
geom_rect() +
geom_text(x=5, aes(y=labelPosition, label=label, color=Group), size=6) +
scale_fill_manual(values = c('Increase' = primary_color, 'No Change' = '#FFFFFF', 'Decrease' = secondary_color)) +
scale_color_manual(values = c('Increase' = primary_color, 'No Change' = '#FFFFFF', 'Decrease' = secondary_color)) +
coord_polar(theta="y") +
xlim(c(-1, 5)) +
theme_void() +
theme(legend.position = "none")
ggsave(file.path(output.path,'donut_freq_change_by_state.pdf'),
width = 8, height = 8, units = 'in')
ggplot(df.state.freq_by_decade, aes(map_id = str_to_lower(Region))) +
geom_map(aes(fill = freq_quantitle), map = fifty_states) +
expand_limits(x = fifty_states$long, y = fifty_states$lat) +
scale_fill_manual(values = c('#FFFFFF', '#FDE9D9', '#FAD3B3', '#F7BC8D', primary_color)) +
coord_map('polyconic') +
scale_x_continuous(breaks = NULL) +
scale_y_continuous(breaks = NULL) +
labs(x = '', y = '') +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text.x = element_blank(),
axis.text.y = element_blank(),
axis.title.x = element_blank(),
axis.title.y = element_blank(),
axis.ticks = element_blank(),
legend.position = 'bottom'
)
ggsave(file.path(output.path,'map_percent_frequency_increase_by_state.pdf'),
width = 20, height = 10, units = 'in')